Two Questions for Scene Text Recognition
Since the introduction of the end-to-end network CRNN, Scene Text Recognition (STR) has embarked on a fast-paced journey driven by deep learning. With the continuous emergence of new methods, the accuracy of the six commonly used benchmarks in the STR field has been steadily improving. As shown below, the latest advancements in the STR field are exhibiting a saturation trend in accuracy. The challenges posed by the commonly used benchmarks appear to have been "solved," evident in the narrow room for improvement in accuracy and the recent deceleration in performance gains by SOTA models.
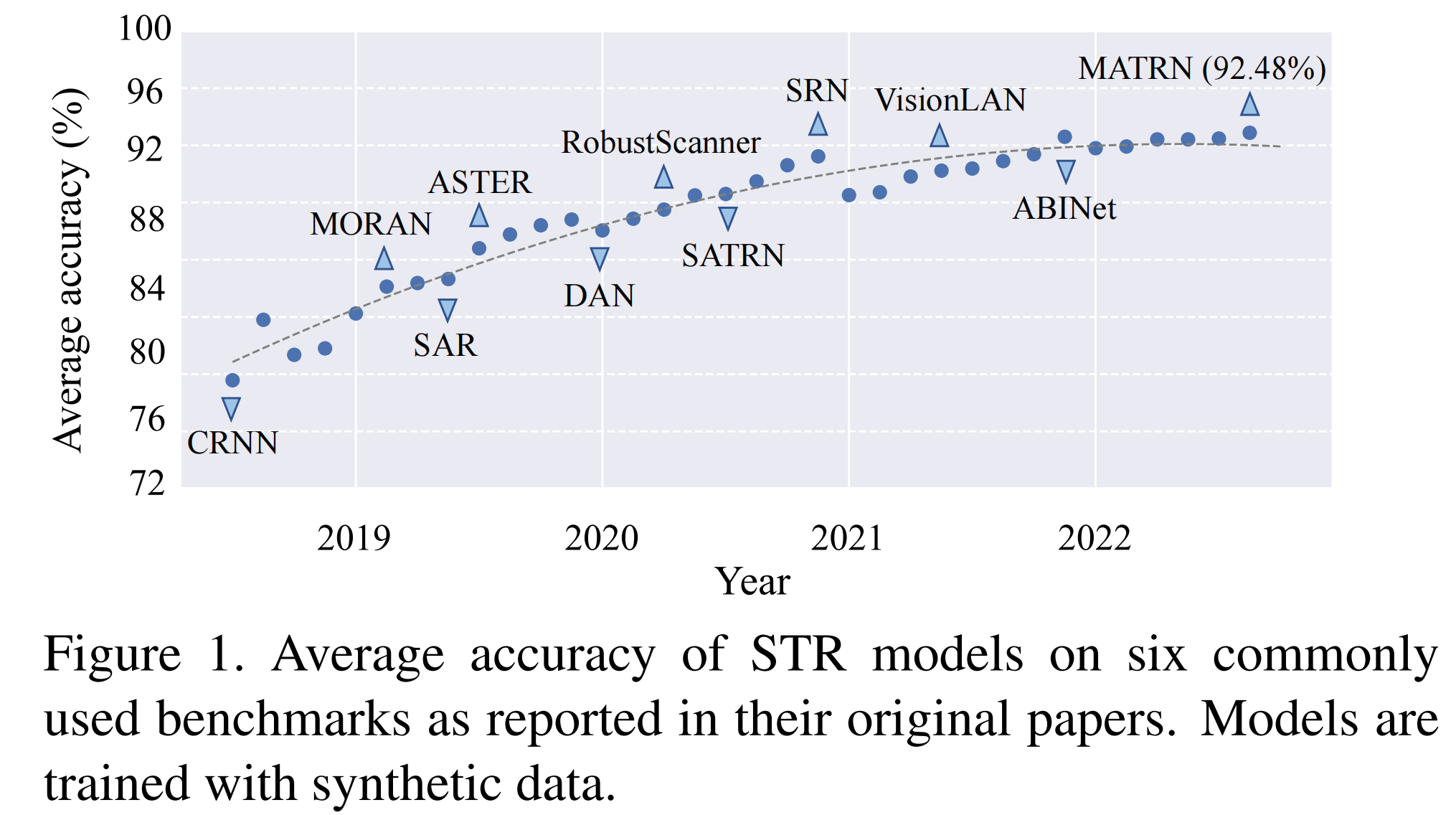
This phenomenon has prompted us to raise the following two questions: 1) Are the commonly used benchmark still sufficient to drive future progress in the field of STR? 2) Does the saturation of accuracy in these benchmark imply that the problem of STR has been solved?
Q1: Are common benchmarks remain challenging?
we start by selecting 13 representative models, including CTC-based, attention-based and language model-based models. We evaluate their performance on the six STR benchmarks to find their joint errors. As depicted below, only 3.9% (298 images) of the total 7672 benchmark images can not be correctly recognized by any models. And there might be only 1.53% scope for accuracy improvement. Therefore, the common benchmarks give limited insight into future STR research.
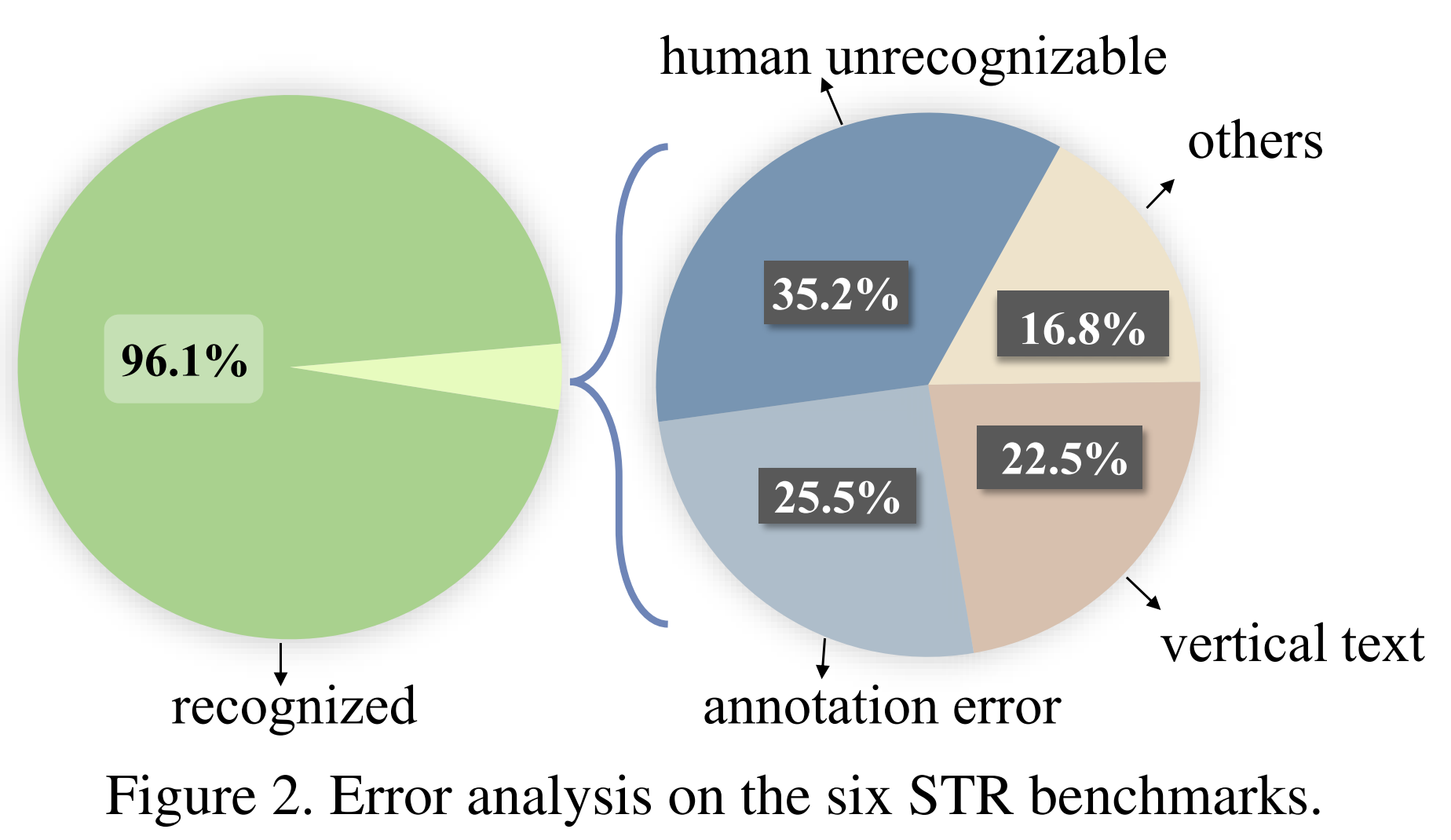

Q2: Is STR solved or challenges are obscured?
While the benchmarks for STR have somehow reached their upper limits, it does not necessarily imply that the problem of STR has been completely solved. To address this question, we constructed a large-scale, real-world scene text recognition dataset called Union14M. Union14M is composed of 17 publicly available datasets, including 4 million labeled data samples (Union14M-L) and 10 million high-quality unlabeled data samples (Union14M-U). As shown below Union14M encompasses diverse real-world scenes, such as curved text, multi-oriented text, artistic fonts, text on complex backgrounds, and blurred/occluded text. It can be viewed as a comprehensive mapping of text distributions in real-world scenarios, enabling us to evaluate the performance of STR models in more complex and diverse real-world scenes.

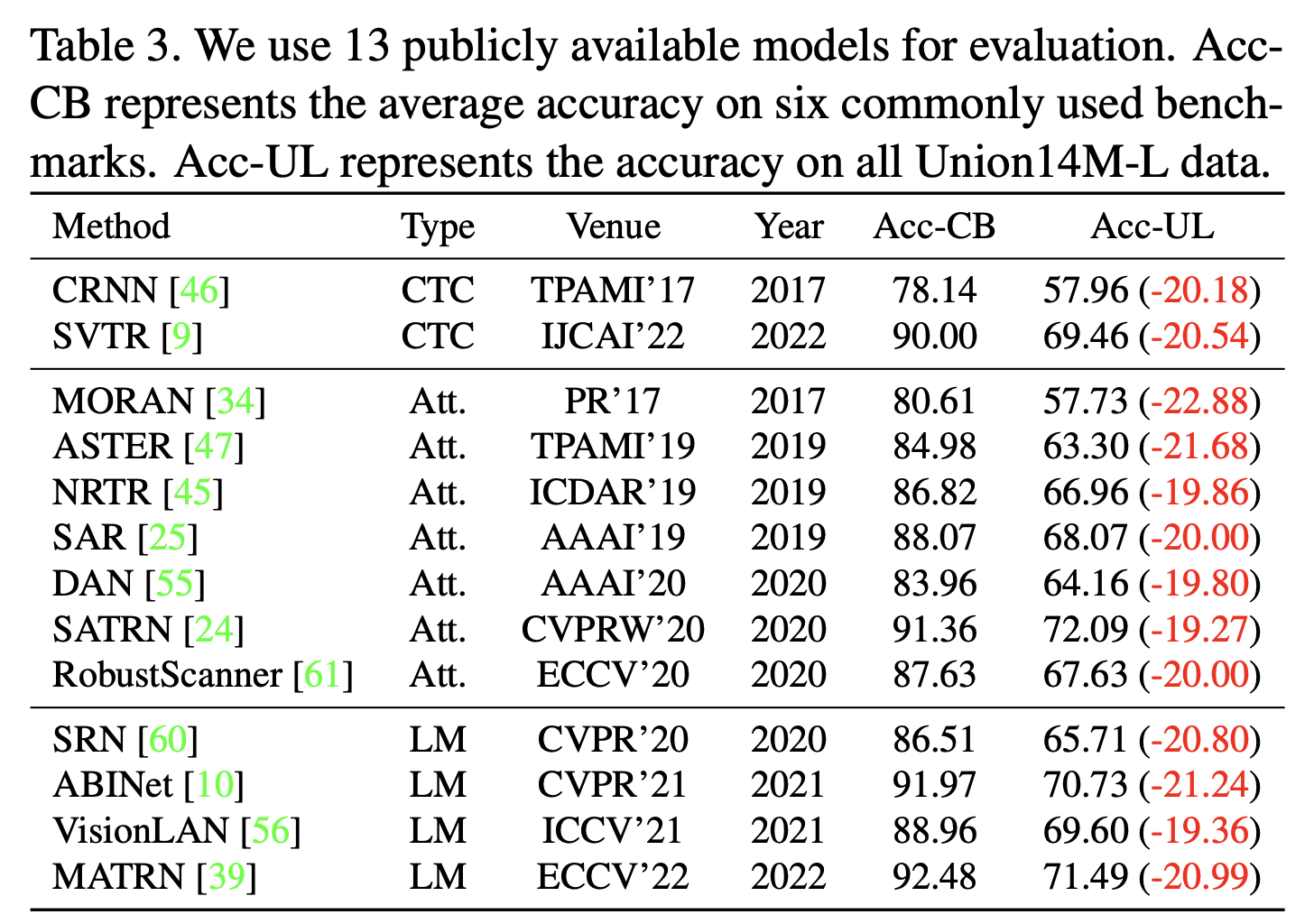
We conducted experiments using Union14M-L on 13 STR algorithms, comparing their accuracy on both the commonly used benchmarks and Union14M-L. As shown in below, although the 13 STR algorithms achieved high performance on the commonly used STR benchmarks, they exhibited an average accuracy drop of 20.50% on Union14M-L. This indicates that existing STR algorithms trained on synthetic data lack generalization and are far from meeting the demands of real-world scenarios. It also addresses the previous question: STR is far from being solved.
Remaining Challenges for STR
We sumarized seven challenges for STR in real-world scenarios through error analysis on Union14M-L. Details can be find in our paper
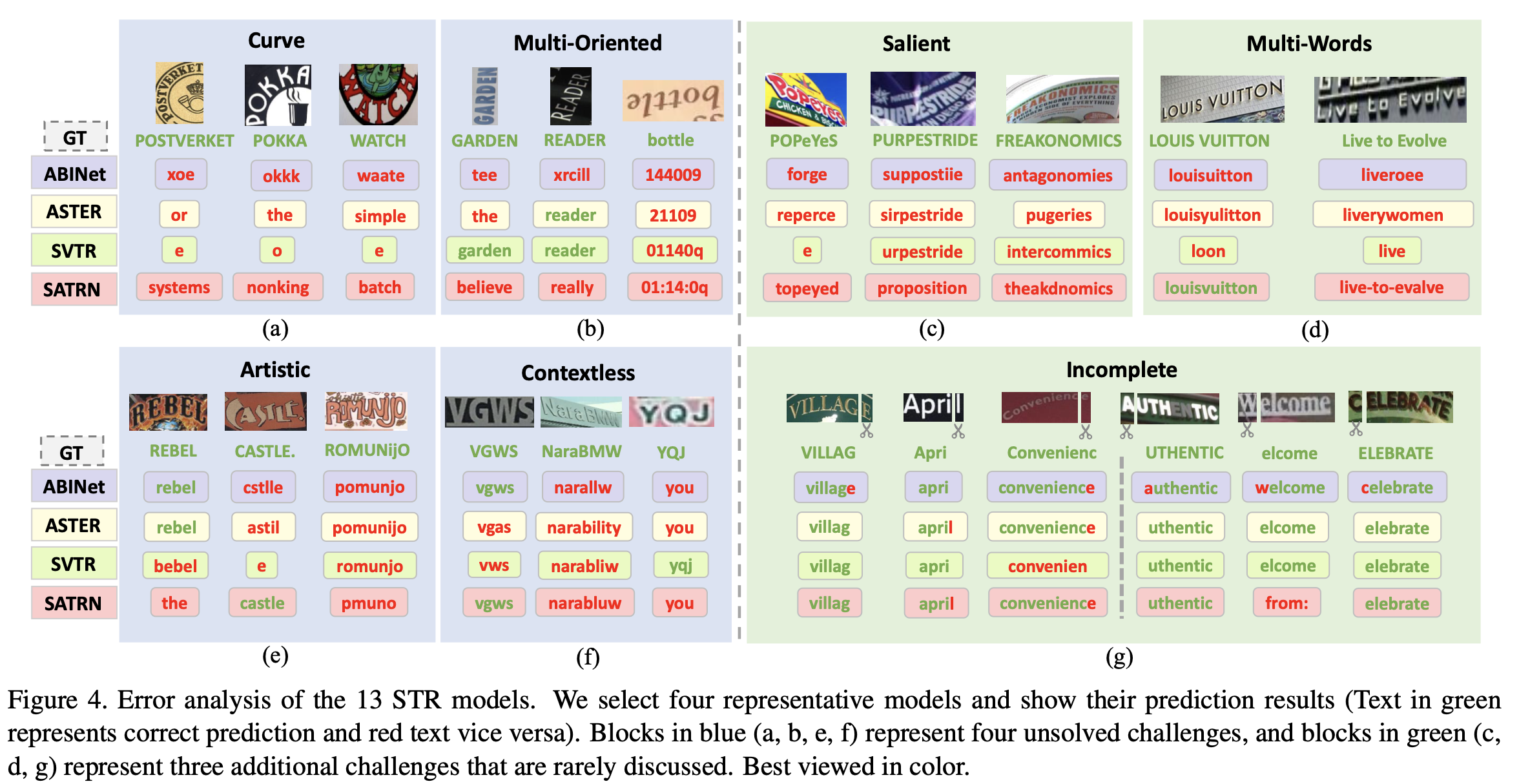
To assess STR models in a more comprehensive range of real-world scenarios and promote future research on the seven challenges mentioned earlier, we have constructed a question-driven benchmark called Union14M-Benchmark. It consists of eight subsets, comprising a total of 409,393 images.

Benchmar Experiments
We conducted benchmark tests on the aforementioned 13 STR models using Union14M-L to provide more quantitative analysis conclusions. The results are presented in Table 5.
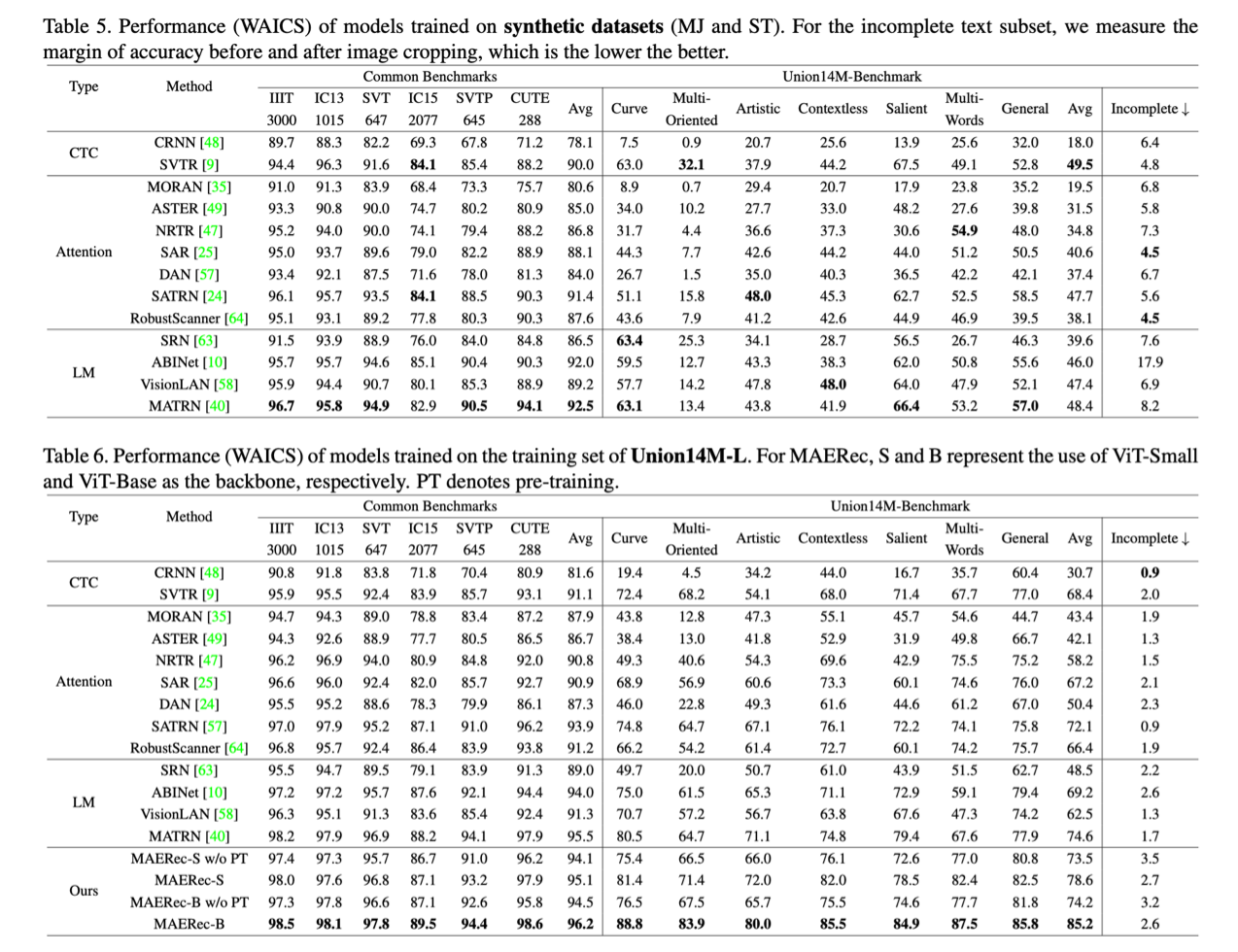
- Conclusion 1: Real-world data is challenging. As shown in Tables 5 and 6, compared to the commonly used benchmarks, the average accuracy of models on Union14M-Benchmark decreased by 48.5% and 33.0% when trained on synthetic datasets and Union14M-L, respectively. This indicates that text images in real-world scenarios are more complex than those in the six commonly used benchmarks.
- Conclusion 2: Real-world data is effective. Models trained on Union14M-L can achieve an average accuracy improvement of 3.9% on the commonly used benchmarks and a 19.6% improvement on Union14M-Benchmark. The relatively small performance improvement on the common benchmarks also suggests their saturation state.
- Conclusion 3: STR is still far from being solved. When trained only on Union14M-L, we observed a maximum average accuracy of only 74.6% on Union14M-Benchmark. This indicates that STR is far from being solved. Although relying on large-scale real-world data can bring certain performance improvement, further research is still needed in the STR community.
MAERec: A Real-world Adapted Recognizer
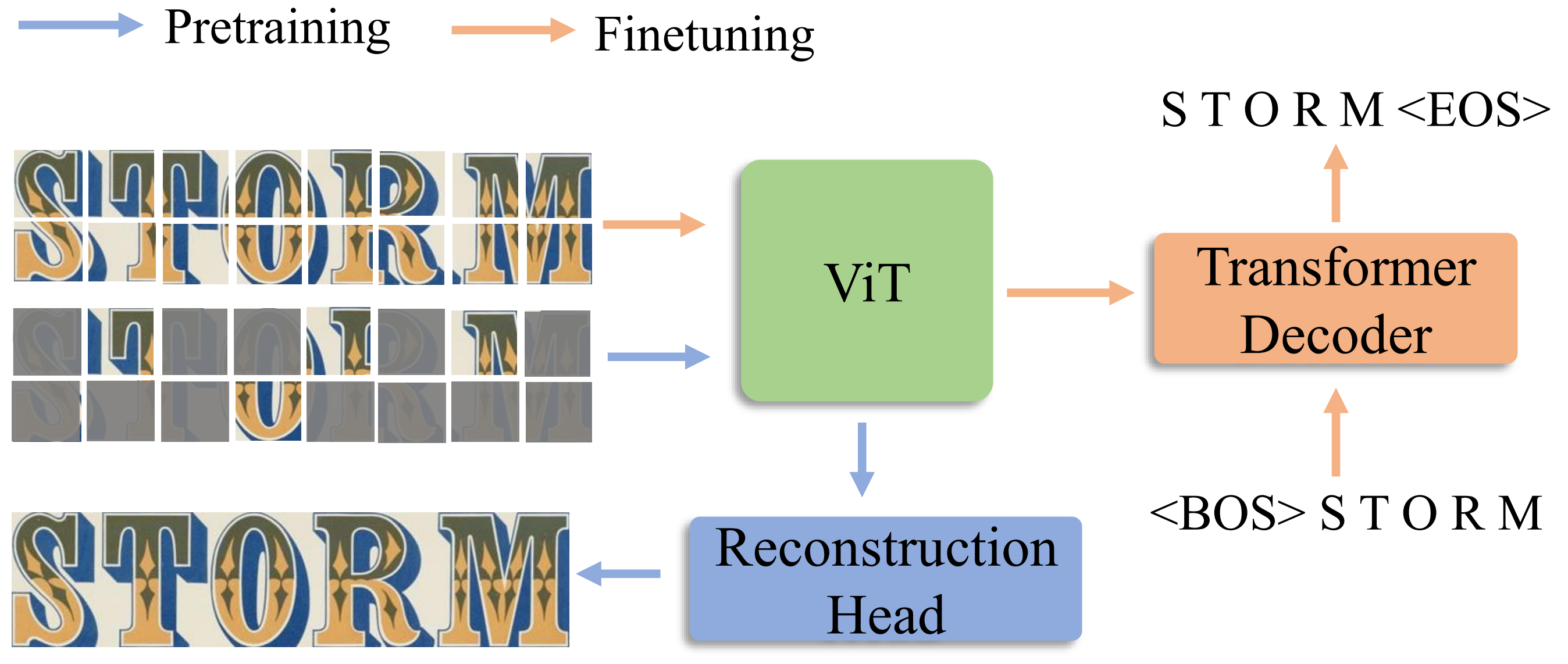
To further explore the potential of addressing STR from a data perspective, we propose a scene text recognizer called MAERec, which is based on self-supervised pre-training using the MAE paradigm. To leverage the 10 million unlabeled images in Union14M-U, we pre-train the ViT backbone network in MAERec using the MAE pre-training paradigm. After pre-training, we initialize MAERec with the pre-trained ViT weights and fine-tune the entire model on Union14M-L. When using ViT-Base as the backbone network, MAERec achieves an average accuracy of 85.2% on Union14M-Benchmark. This result demonstrates that utilizing large-scale unlabeled data can significantly improve the performance of STR models in real-world scenarios and warrants further exploration.
BibTeX
@inproceedings{jiang2023revisiting,
title={Revisiting Scene Text Recognition: A Data Perspective},
author={Qing Jiang and Jiapeng Wang and Dezhi Peng and Chongyu Liu and Lianwen Jin}
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
year={2023}
}